

Selama bertahun-tahun, banyak organisasi mengandalkan pemeriksaan uptime sederhana untuk menilai kesehatan database. Meskipun mengetahui bahwa database Anda berjalan tentu penting, uptime saja hampir tidak memberikan informasi apa pun tentang kinerja, efisiensi, atau pengalaman pengguna. Secara teknis, database dapat berada dalam keadaan “aktif” meskipun menghasilkan query yang sangat lambat, mengalami persaingan sumber daya, atau berada di ambang kelelahan kapasitas. Pemantauan database modern memerlukan pendekatan yang lebih canggih yang berfokus pada metrik yang benar-benar memengaruhi aplikasi dan pengguna Anda.
Metrik Kinerja Query
Area yang paling kritis untuk dipantau adalah kinerja query, karena query adalah tempat di mana database Anda berinteraksi langsung dengan aplikasi Anda. Query yang berjalan lama seringkali menjadi pertanda awal masalah yang lebih dalam. Dengan memantau waktu eksekusi query, Anda dapat mengidentifikasi query spesifik mana yang mengonsumsi sumber daya berlebihan dan menyebabkan bottleneck. Sama pentingnya adalah memahami waktu tunggu query, yang mengungkapkan apa yang ditunggu oleh query Anda, apakah itu akses disk, kunci, atau sumber daya jaringan.
Selain waktu eksekusi, menganalisis query teratas berdasarkan penggunaan CPU membantu Anda mengidentifikasi operasi mana yang paling memakan sumber daya komputasi. Demikian pula, melacak query berdasarkan jumlah pembacaan dan penulisan yang mereka lakukan dapat menyoroti pola akses data yang tidak efisien, yang mungkin dapat dioptimalkan melalui optimasi indeks atau refaktoring query. Metrik-metrik ini mengubah masalah kinerja yang abstrak menjadi wawasan konkret dan dapat ditindaklanjuti.
Utilisasi dan Kapasitas Sumber Daya
Meskipun penggunaan CPU dan memori mungkin terlihat seperti metrik dasar, memahami keduanya dalam konteks yang tepat sangat penting. Pola penggunaan CPU dapat memberi tahu Anda apakah server database Anda memiliki daya pemrosesan yang cukup untuk beban kerja Anda, tetapi yang lebih penting, penggunaan CPU yang tinggi secara berkelanjutan dapat menandakan adanya indeks yang hilang atau query yang tidak dioptimalkan dengan baik, bukan sekadar kekurangan hardware.
Metrik memori layak mendapat perhatian khusus karena database sangat bergantung pada caching untuk mencapai kinerja yang baik. Rasio hit buffer cache, yang mengukur persentase permintaan data yang dilayani dari memori daripada disk, sebaiknya melebihi 90 persen. Ketika rasio ini turun, hal itu menunjukkan bahwa database Anda sering mengakses disk untuk data, yang secara drastis memperlambat kinerja. Memantau alokasi memori seiring waktu juga membantu dalam perencanaan kapasitas, menunjukkan apakah jejak memori database Anda tumbuh pada tingkat yang berkelanjutan.
Metrik I/O disk melengkapi gambaran sumber daya. Melacak operasi baca dan tulis disk per detik, serta waktu respons disk rata-rata, membantu Anda memahami apakah penyimpanan menjadi bottleneck. I/O jaringan sama pentingnya untuk memahami seberapa banyak data yang mengalir antara database dan aplikasi Anda.
Aktivitas Koneksi dan Sesi
Pemantauan koneksi aktif dan detail sesi memberikan gambaran tentang cara aplikasi Anda sebenarnya menggunakan database. Pemantauan koneksi pengguna saat ini membantu Anda memahami beban kerja bersamaan dan dapat memberi peringatan tentang kelelahan pool koneksi sebelum menyebabkan kegagalan aplikasi. Pemantauan pola koneksi seiring waktu juga mengungkapkan tren penggunaan yang dapat digunakan untuk pengambilan keputusan perencanaan kapasitas.
Pemantauan kunci (lock) sangat kritis untuk memahami masalah persaingan (contention). Ketika query menunggu kunci yang dipegang oleh sesi lain, pengguna mengalami penundaan yang tidak dapat dijelaskan oleh metrik CPU atau memori sederhana. Dengan melacak kunci yang saat ini dipegang dan sesi yang menunggu kunci, Anda dapat mengidentifikasi pola transaksi bermasalah atau transaksi yang berjalan lama yang menghalangi pekerjaan lain.
Mengukur Metrik dengan Navicat Monitor
Navicat Monitor menyediakan arsitektur tanpa agen untuk memantau database MySQL, MariaDB, PostgreSQL, dan SQL Server, artinya Anda tidak perlu menginstal perangkat lunak di server database itu sendiri. Alat ini mengumpulkan metrik secara berkala dan menyimpannya di database repositori untuk analisis historis dan tren.
Untuk pemantauan kinerja query, grafik Quey Berjalan Lama Navicat Monitor menampilkan query teratas berdasarkan durasi eksekusi, jenis penundaan, penggunaan CPU, dan operasi baca/tulis. Hal ini memungkinkan Anda untuk dengan cepat mengidentifikasi query bermasalah dan menyelidiki karakteristik eksekusinya. Alat ini menyimpan data historis sehingga Anda dapat melacak apakah kinerja query menurun seiring waktu.
Pemantauan sumber daya di Navicat Monitor mencakup seluruh spektrum metrik sistem. Aplikasi ini mengumpulkan beban CPU, penggunaan RAM, dan berbagai sumber daya sistem lainnya melalui SSH atau SNMP, memberikan visibilitas terhadap kinerja baik di tingkat database maupun sistem operasi. Dashboard interaktif menampilkan grafik real-time dan historis yang menunjukkan beban server, penggunaan disk, I/O jaringan, dan kunci tabel, memudahkan Anda untuk mengkorelasikan metrik yang berbeda dan mengidentifikasi pola.
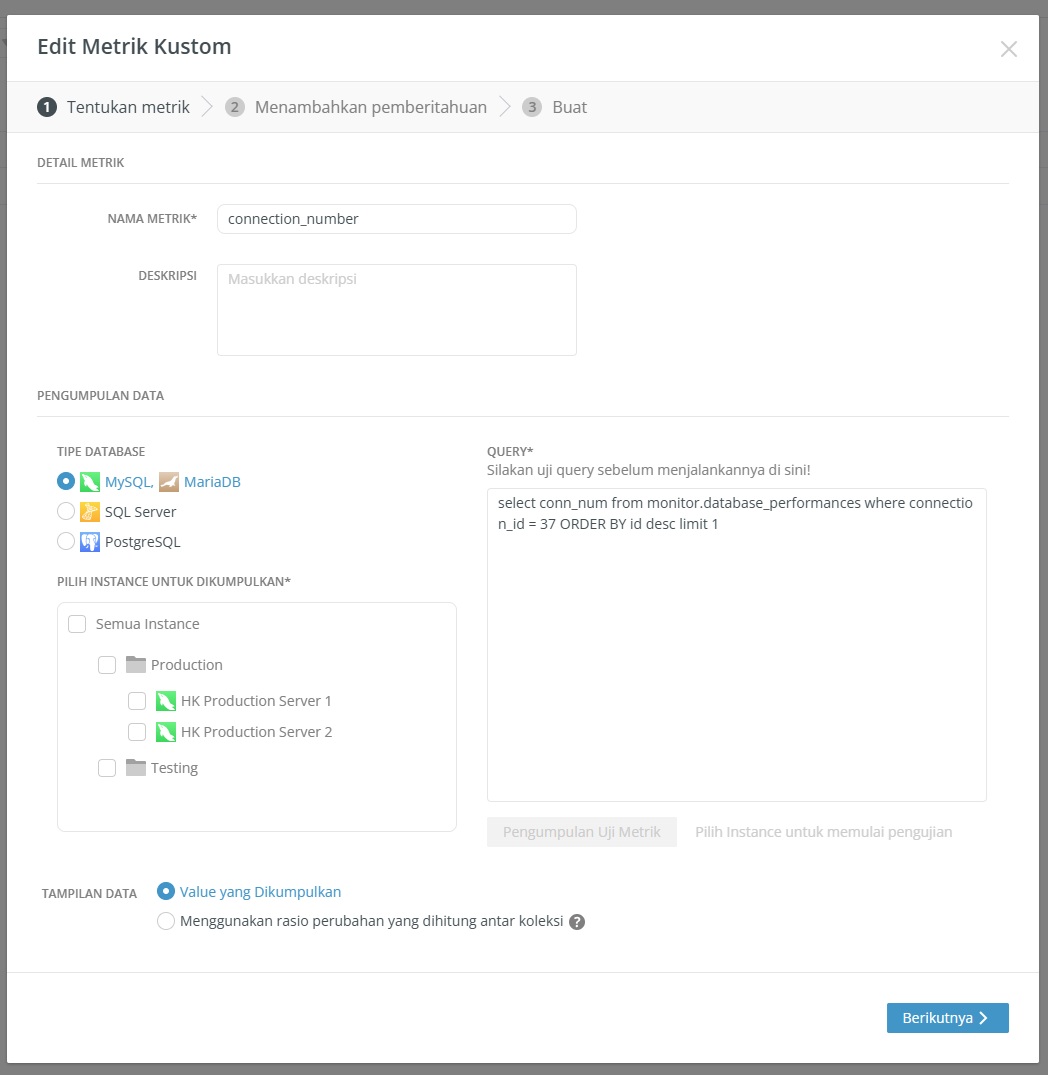
Salah satu fitur yang sangat powerful adalah kemampuan metrik kustom. Anda dapat menulis query sendiri untuk mengumpulkan metrik kinerja untuk instance tertentu dan menerima pemberitahuan saat nilai melebihi ambang batas yang ditentukan. Ini berarti Anda dapat memantau indikator bisnis spesifik atau karakteristik kinerja khusus yang penting bagi aplikasi Anda, melampaui metrik bawaan standar.
Sistem pemberitahuan di Navicat Monitor memfasilitasi pengelolaan proaktif dengan memberi tahu Anda saat metrik melebihi ambang batas yang dapat dikonfigurasi. Anda dapat mengatur peringatan untuk metrik apa pun, termasuk metrik kustom, dan mendefinisikan nilai ambang batas serta berapa lama nilai tersebut harus melebihi ambang batas sebelum memicu peringatan. Pemberitahuan dapat dikirim melalui email, SMS, SNMP, atau Slack, memastikan tim Anda mengetahui masalah sebelum memengaruhi pengguna. Alat ini menyediakan analisis peringatan terperinci yang mencakup grafik metrik, garis waktu, dan konteks historis untuk membantu analisis akar masalah.
Melampaui Dashboard: Mengubah Metrik Menjadi Tindakan yang Dapat Dilakukan
Pengumpulan metrik hanyalah langkah pertama. Nilai sebenarnya terletak pada pemahaman pola, penetapan batas normal yang tepat, dan pembuatan peringatan yang dapat ditindaklanjuti. Alih-alih hanya memantau dashboard, tetapkan rentang normal untuk metrik kunci Anda berdasarkan data historis dan pola beban kerja. Hal ini memungkinkan Anda menetapkan ambang batas peringatan yang cerdas untuk mendeteksi masalah nyata tanpa memicu peringatan palsu akibat variasi normal.
Pertimbangkan hubungan antara metrik saat menyelidiki masalah. Peningkatan tajam dalam disk I/O mungkin terkait dengan penurunan rasio hit cache buffer dan peningkatan waktu eksekusi query. Memahami hubungan ini membantu Anda mengidentifikasi penyebab akar masalah daripada hanya gejala. Rapat tinjauan perencanaan kapasitas secara teratur menggunakan tren historis memastikan Anda dapat melakukan skalabilitas secara proaktif sebelum mencapai batasan sumber daya.
Beralih dari pemantauan uptime sederhana ke pemantauan kinerja komprehensif akan berdampak signifikan pada cara Anda memahami dan mengelola database Anda. Dengan fokus pada metrik yang secara langsung memengaruhi kinerja aplikasi dan pengalaman pengguna, Anda dapat beralih dari penanganan masalah secara reaktif ke optimasi proaktif, memastikan database Anda memberikan kinerja yang konsisten dan andal.







